DevSecOps
Projets
DevSecOps
Monitoring VPS, Prometheus & Grafana
Stack d'observabilité auto-hébergée sur VPS ARM64 pour surveiller la santé du serveur et de tous ses conteneurs Docker. Métriques système et par conteneur, dashboards temps réel derrière VPN.
Par Sehenonirina Elisa Randriamasinoro, M1 Cybersécurité des Systèmes Embarqués, UBS Lorient
Code source20269 stack
[PROMETHEUS][GRAFANA][NODE EXPORTER][CADVISOR][DOCKER][TRAEFIK][WIREGUARD][ORACLE CLOUD][ARM64]
Contexte
Mon VPS héberge plusieurs services : ce portfolio, un VPN WireGuard, Umami, Wazuh, une landing page. Tant que tout tourne, on ne se pose pas de questions. Mais quand un conteneur consomme trop de RAM ou qu'un disque se remplit, je voulais le voir venir au lieu de le découvrir quand le serveur rame.
J'ai monté une stack d'observabilité classique : Prometheus pour collecter les métriques, Grafana pour les visualiser. L'objectif était de comprendre la chaîne complète, pas juste d'installer un dashboard tout fait.
Architecture
VPS Oracle Cloud (ARM64 — Ubuntu 24.04) │ ├── Node Exporter ← métriques système (CPU, RAM, disque, réseau) ├── cAdvisor ← métriques par conteneur Docker │ ├── Prometheus ← scrape Node Exporter + cAdvisor toutes les 15s │ stocke les séries temporelles (rétention 30j) │ └── Grafana ← interface de visualisation (VPN-only via Traefik)
Chaque brique a un rôle précis :
- Node Exporter expose les métriques de la machine hôte
- cAdvisor lit le démon Docker et expose les métriques de chaque conteneur
- Prometheus interroge ces deux sources à intervalle régulier et stocke tout
- Grafana lit Prometheus et trace les graphiques
Le rôle de Prometheus
Prometheus fonctionne en pull : ce n'est pas Node Exporter qui envoie ses données, c'est Prometheus qui vient les chercher. Sa configuration liste simplement les cibles à scraper :
scrape_configs:
- job_name: node
static_configs:
- targets: [node-exporter:9100]
- job_name: cadvisor
static_configs:
- targets: [cadvisor:8080]YAMLToutes les 15 secondes, Prometheus interroge ces endpoints, récupère les métriques et les stocke. La page Target health permet de vérifier d'un coup d'œil que chaque source répond bien.
Visualisation dans Grafana
Une fois Prometheus branché comme source de données, Grafana affiche tout. La capture montre le dashboard Node Exporter Full sur mon serveur : pression CPU, charge système, RAM utilisée, swap, espace disque, trafic réseau.
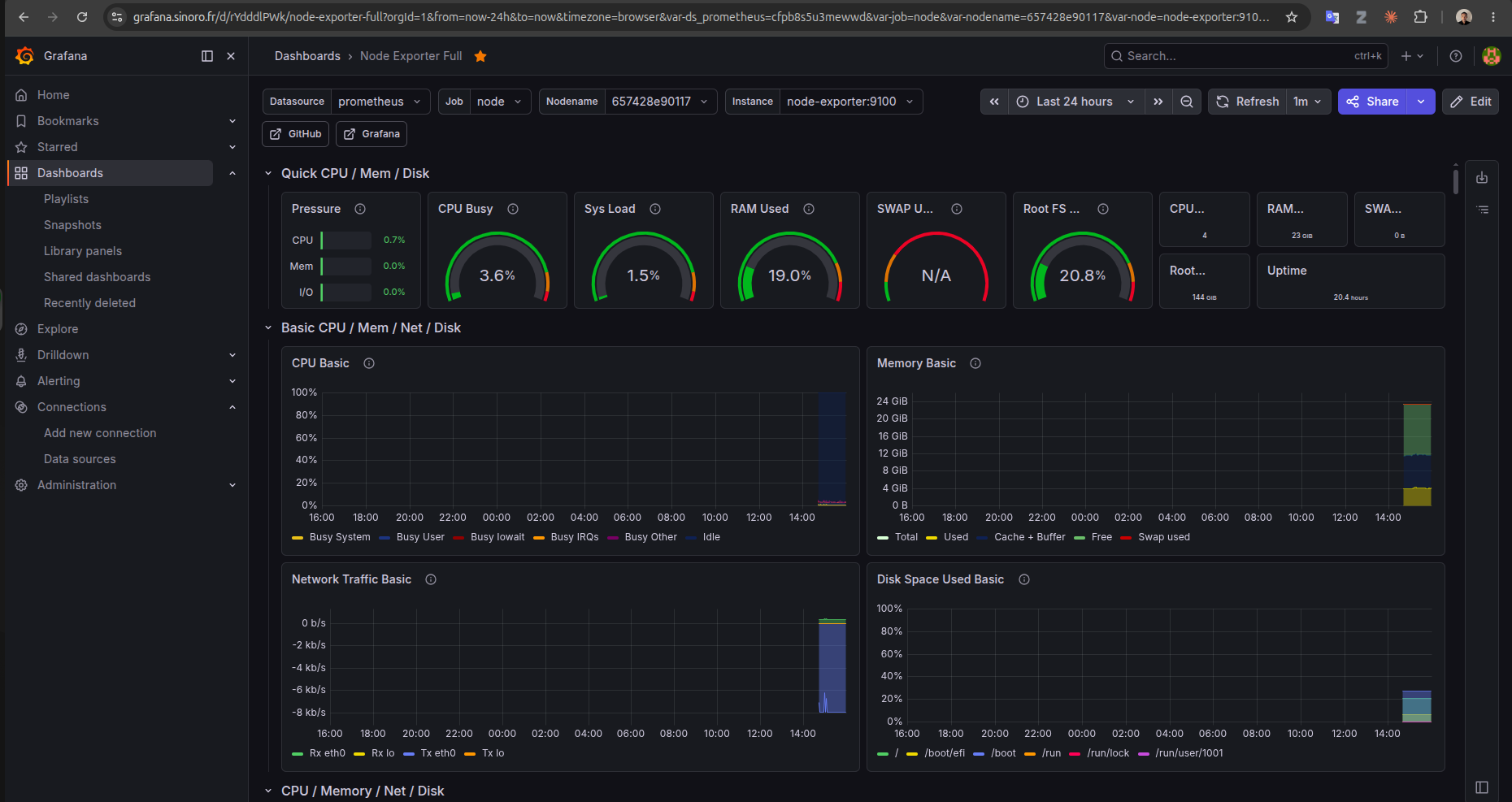
Pour les conteneurs, un second dashboard branché sur cAdvisor donne la consommation CPU/RAM/réseau de chaque service Docker individuellement : je vois précisément ce que coûte le portfolio, Umami ou Wazuh.
Accès réservé via VPN
Comme le reste de mon homelab, les dashboards ne sont pas exposés sur Internet. Grafana et Prometheus passent par Traefik, avec un middleware qui n'autorise que le sous-réseau WireGuard :
traefik.http.middlewares.monitoring-vpn.ipwhitelist.sourcerange=10.8.0.0/24,127.0.0.1/32
Sans être connecté au VPN, une requête sur grafana.sinoro.fr reçoit un 403. Les exporters (Node Exporter, cAdvisor) ne sont eux jamais exposés du tout : seul Prometheus les joint, sur un réseau Docker interne.
Un détail qui m'a appris quelque chose
Au premier déploiement, Grafana renvoyait des 504 Gateway Timeout. Le certificat était bon, le DNS correct, Grafana répondait en interne, mais Traefik n'arrivait pas à l'atteindre.
La cause : Grafana était sur deux réseaux Docker (un interne pour parler à Prometheus, un pour Traefik). Quand un conteneur est sur plusieurs réseaux, Traefik utilise le premier de la liste pour le joindre, et il tombait sur le réseau interne où Traefik n'est pas présent. Mettre le réseau Traefik en premier dans la déclaration a réglé le problème.
C'est typiquement le genre de bug qu'on ne comprend qu'en lisant les logs étape par étape, et qui apprend beaucoup sur la façon dont Traefik route réellement le trafic.
Projets similaires
Tous les projetsDevSecOpsCybersécurité
Indian Food, Landing page DevSecOps
DevSecOpsCybersécurité